Data Platform — Solution for Consumption (Part 2)
In the architecture of a Data Platform, the consumption layer comprises the tools for data persistence, storage, cataloging, and processing. As mentioned in the previous article, the biggest problem with commercial Data Warehouse solutions is their highly coupled and poorly scalable nature.
To address these challenges, we need to revisit the architecture of a generic Database Management System (DBMS) and rebuild its components to compose a consumption solution for the Data Platform:

We can divide the architecture above into four main components:
- Computation Engine: the component that receives the query, coordinates its execution, and performs all transformations and aggregations.
- Catalog Manager: where information about table structures and metadata is stored.
- Storage Engine: where the logical units of the database are defined and where data access methods are specified.
- Permanent Memory: the persistence layer where the data is actually stored.
Now, let’s go through each of these components, rebuilding each piece to compose our own consumption solution for the Data Platform and solve the most crucial problems from commercial solutions.
Permanent Memory
This is where we start, and it’s where the data is actually persisted. The main characteristics of permanent memory that we seek, given the challenges for our platform, are:
- Easily scalable
- Allowing distributed consumption to avoid being a performance bottleneck
The two most common market solutions are Object Storage and Distributed File System (such as HDFS). For comparison, here is a table with some of the main differences based on solutions offered by AWS:
Distributed File Systems, despite their higher cost and maintenance fees, are still a reality justified by their “infinitely” scalable performance, given that their transfer rates are unrestricted and only dependent on cluster configurations.
Object Storage, although having provider-limited transfer rates, is a much more accessible choice with almost no maintenance requirements. It has become the obvious choice in the vast majority of Data Platforms.
So we can assume the choice of an Object Storage (S3) as our permanent memory.

Storage Engine
Our next step will be to define the data serialization format to be stored in Permanent Memory, which will fulfill the role of the Storage Engine.
To meet our analytical needs in a Data Platform, we seek a serialization optimized for reading and aggregation. Columnar formats are the most optimized for this purpose. In this regard, Parquet and ORC are two of the most popular columnar formats, and we can draw the following shallow comparison between them:
ORC performance usually shows better results in internet-found benchmarks and, in most practical cases, this is due to the data statistics being embedded in the file itself and also due to its more efficient compression.
The choice here, however, is somewhat trivial, as these differences are not glaring and what usually defines the choice is the ecosystem that makes up your architecture. For our Platform, however, we will opt for ORC.

Catalog Manager
The main task of the Catalog Manager is to store table definitions and metadata. Ideally, we seek a modular tool by nature so that it can be consumed by different systems, centralizing data and table definition management within itself.
Here, the existing solutions are very few, with Hive Metastore being the choice of the overwhelming majority of Platforms. And for our Platform, it doesn’t need to be different, given the naturalness with which it integrates with the most common data ecosystem tools.

Computation Engine
The Compute Engine is the consumption engine and also the entire interface for users, assuming one of the main roles in our Data Platform. It is the component that receives the user’s query request, transcribes it into its execution tree, optimizes its form, coordinates the projection that will be sent to the storage layers, performs all other Relational Algebra operations, and returns the result to the user. It’s no wonder that this is one of the most difficult choices, as there are many options available. For this article, however, I will focus on the two most popular solutions:
PrestoDB
- Query Engine, focused on query execution
- Excellent ANSI-SQL compliance
- Geared towards immediate and Ad Hoc queries
- Capable of federating multiple distinct bases
Spark
- General Compute Engine, a general-purpose tool for distributed computing
- DSL in Python, Java, and Scala that facilitates exploratory analysis and application building
- Geared towards applications and long-running queries
- Excellent for manipulating and persisting data
As we can see, these are tools with very distinct qualities, standing out within their application and serving different use cases.
In most scenarios, Data Scientists and Developers benefit more from the general-purpose computational nature of Spark, bringing greater flexibility through its programmatic DSL available in some programming languages, in addition to the SQL interface. Moreover, it was built assuming that processing failure is a certainty, so its computations are highly tolerant, making it a framework for application development.
On the other hand, Data Analysts and people more accustomed to the SQL interface benefit from the nature optimized for Ad Hoc queries of PrestoDB. It is optimized almost solely for these fast analytical queries, and because of this, many benchmarks have shown superior performance for this task.
With our architecture sufficiently decoupled, we do not need to choose between one or the other, and in most cases, we will even choose both options to meet different needs. Therefore, the final design of our Data Platform’s consumption architecture would look like this:
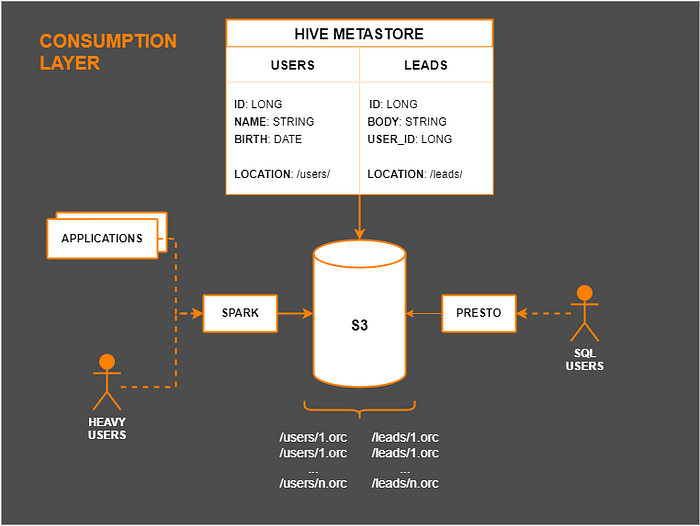
With this architecture, we have already solved many of the challenges mentioned earlier with the decoupling of systems, storage and processing with high scalability, the data catalog centralizing information on the structure of tables and being shared by multiple consumption tools focused on specific needs.
It seems that we are ready to consume the data. But where do the data come from? This is the question we will address in the next topic.
Next: Coming soon
